

"How good is Drupal for SEO?" The answer: great Drupal SEO is easy to implement with the right strategy, information and modules.
SME Pals is reader-supported. When you buy through links on our site, we may earn an affiliate commission. Learn more.

When to use robots.txt and 301 redirects for SEO
Use robots.txt and 301 redirects to "shape" your content into a Google search friendly high-traffic machine while avoiding common pitfalls that can lead to potentially disastrous drops in organic search traffic.

The best way to rank well in Google is to understand your niche market. Know how it works. Know who links to who and why.
Huge Drop in Traffic?
A significant drop in Google organic traffic is not necessarily indicative of a penalty.
Definitely ensure that there are no technical issues preventing your site ranking - like accidentally blocking content with robots.txt. But be aware that SEO won't necessarily make your site rank well, or recover lost traffic. It can only help give your site a 'chance' of ranking.
Until you have become popular Google will happily rank thin (or even entirely blank) pages from bigger websites above your content.
The more you know the better the chances you have of building valuable relationships that deliver a strong backlink profile from genuine citations and editorial links.
Google doesn't want to make sites popular by ranking them. It wants to rank popular sites.
SEO Recovery
Research your niche market and competitors to quickly understand why they're successful and how you can be too.
![Analyze competitors' backlinks and SEO using SEMRush]()
-
Analyze any competing website using SEMRush and learn the secrets to their success.
Understand your niche to make better marketing decisions, capture higher page rankings in Google, make valuable new connections and boost your earnings quickly.
Don't waste time guessing what it takes to win valuable search keywords. Work out who is winning. Find out who links to them. Build your own backlinks.
Try it out. Research a website right now.
You are able to use SEMRush for free by signing up. However, the free plan is limited to 10 requests per day - thereafter a paid plan is required.
What is robots.txt?
The robots.txt file can be used to control which directories and pages search engines have access to. While the robots file cannot enforce the rules it lays out, most of the important search engines (like Google) will obey robots.txt.
Here's an example of how to prevent Google from crawling a page entitled affiliate_links.html:
User-agent: * Disallow: /affiliate_links.html
You aren't limited to listing each and every file that you wish to be Disallowed.
In fact, there is quite a bit to learn about how to use robots.txt, and every webmaster should have a basic knowledge of how to use this file. I recommend you search Google for more resources on this.
What is a 301 redirect?
301 redirects are extremely important for SEO purposes. A 301 response code tells Google that a page has been permanently moved to a different address. This is obviously important when a page name or path changes, or a domain name change occurs.
Without redirection, Google will treat the same content at a new address as completely new content. And what's worse, it will most likely treat this as duplicate content since the old address is likely still indexed.
301 redirects can be implemented programmatically, or from an .htaccess file. People using hosted website solutions may also not be able to edit .htaccess directly, although leading website builders should provide other ways to implement 301 redirects.
A typical redirect from one page to another looks like this:
Redirect 301 /oldpage.html /newpage.html
URL redirection is actually a lot more powerful and flexible than this quick example, and it is possible to use regular expressions to redirect entire domains, directories, or pretty much anything you like.
Wikipedia has a pretty good URL redirection write-up, if you want to learn more.
When to use robots.txt and 301 redirects for SEO
So robots can block search engines from crawling pages, and 301s can redirect old pages to new pages. Sounds pretty simple, right?
The problem is knowing when to use one and when to use the other, and how to avoid conflict between the two.
Getting things wrong can make your site an easy target for a variety of penalties, or at the very least, undesirable consequences.
More importantly, if your site is currently under a Panda penalty, then it is very likely that understanding and implementing robots and 301s will help your site recover quickly - once you've identified the underlying causes.
Limit usage of robots.txt
Google doesn't like being blocked from crawling pages so it advises that robots is only used when you know absolutely that Google should not be crawling a page or directory. Good examples are log in pages, system report pages, image folders, code folders, or website administration pages.
When it comes to actual content, only pages that may damage your page rankings (such as low quality or thin affiliate pages) should be blocked - although there probably isn't a good reason to have low quality or thin affiliate pages in the first place.
When in doubt, don't block content using robots.txt. Make sure you use 301 redirects or canonical tags to indicate the correct versions of webpages. Restrict robot exclusions to parts of the website that should never be part of Google's index.
Don't use robots to block duplicate content!
Often webpages are accessible by a number of different URLs (this is often true in content management systems like Drupal). The temptation is to block the unwanted URLs so that they are not crawled by Google.
In fact, the best way to handle multiple URLs is to use a 301 redirect and/or the canonical META tag. You can learn more about canonical URLs at Matt Cutts' blog SEO advice: URL canonicalization.
Don't combine robots and 301s
Most commonly, people realise that Google is crawling webpages it shouldn't, so they block those pages using robots.txt and set up a 301 redirect to the correct pages hoping to kill two birds with one stone (i.e. remove unwanted urls from the index and pass PageRank juice to the correct pages). However,
Google will not follow a 301 redirect on a page blocked with robots.txt.
This leads to a situation where the blocked pages hang around indefinitely because Google isn't able to follow the 301 redirect.
Never 301 a robots.txt file
When moving from one domain to another, many webmasters simply set up a 301 redirect at the domain level so that all files and folders on the old domain redirect to the new one.
This works fine, except for the robots file, because any changes you implement in the old robots file will be missed (because it is redirecting to the new file), and any changes you make on the new site will be applied to everything.
To avoid potentially confusing and disastrous SEO situations, its best not to 301 a robots.txt file.
Test robots.txt & 301 redirects
It's quick and easy to test both your robots.txt file and 301 redirects by using Google's Search Console. It comes with a built-in robots file tester that you can access at the robots.txt Tester page, under Crawl.

This will show Google's copy of your robots.txt file and allow to you test any URL on your domain to see if it blocked or not.
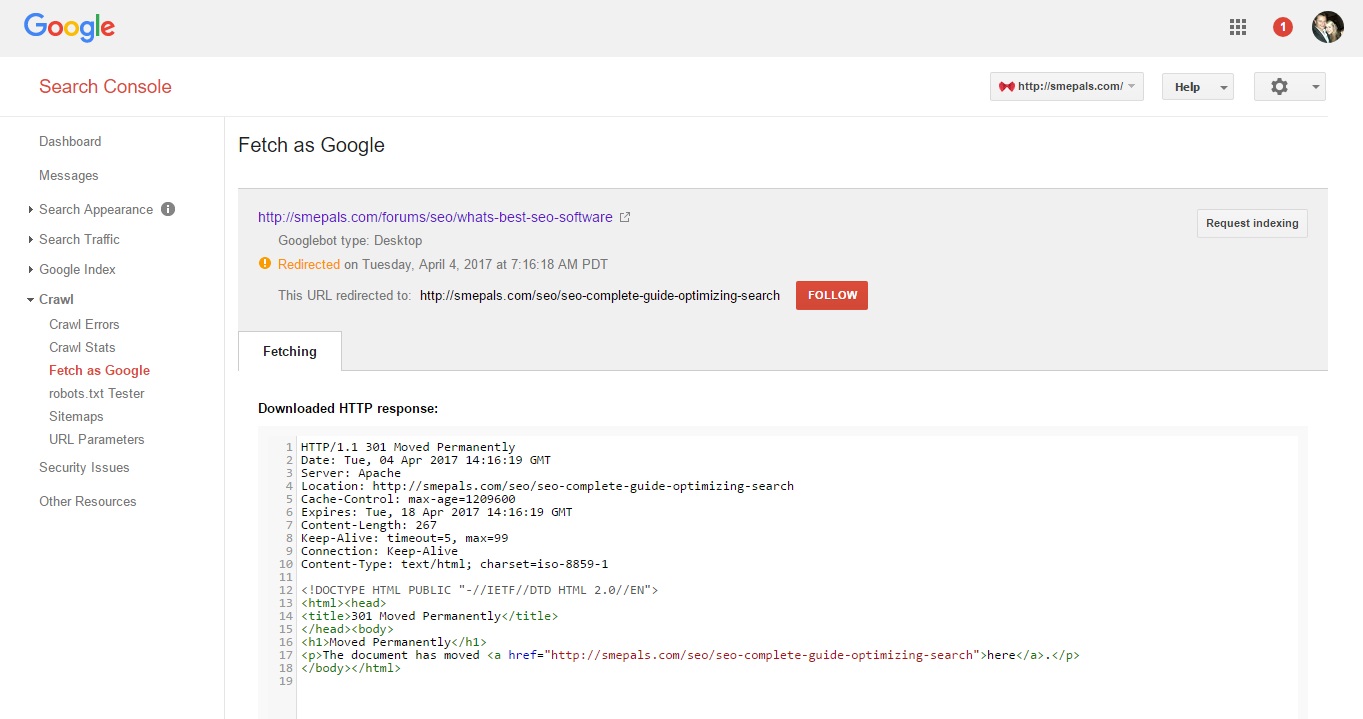
Testing for 301 redirects is equally easy. Go along to the Fetch as Google dialog and enter any URL you like. Google will display the server response code and highlight anything other than a 200 Page Found response.
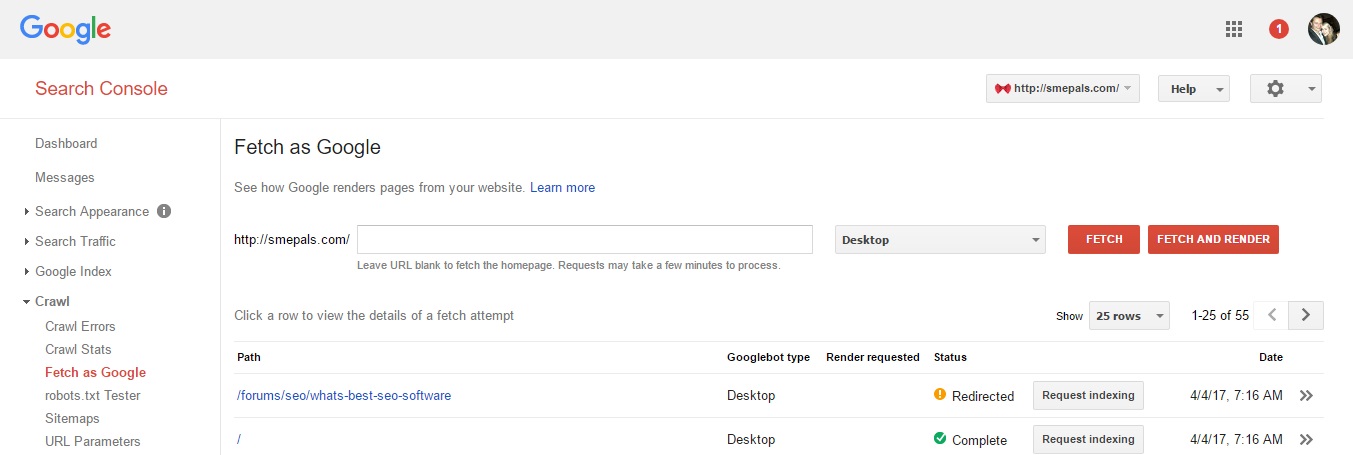
For the purposes of testing if a redirect is working, there's no need to request a full render of the page as this slows things down. However, it is worth clickin g on the result to ensure that the server is responding as you expect (including redirecting to the correct URL).
Those are my SEO tips regarding robots and 301s. What experiences (good or bad) have you had with Google, Panda, SEO and using robots and 301s?
Share your advice and tips in the comments.

Making sure your site enjoys the benefits of high quality, relevant backlinks is about more than creating great content and waiting for nature to take its co
Better Search Engine Optimization (SEO) can mean the difference between capturing high page rankings in Google, for relevant keywords, and remaining

Implementing local SEO (Search Engine Optimization) techniques has become more and more important, from an Internet marketing perspective because, over time,

Google analytics provides a wealth of valuable SEO data. But are you using it to its full potential to help create better content, drive more traffic and convert it more effectively?
It often helps to mine Google analytics data for SEO intelligence with a specific business objective in mind. The analytics and SEO tips covered in this article are all techniques I use to help me decide what new content to create, and whether or not my content is making an impact.

Really unique and clever business ideas don't come along all that often, and when they do I feel obliged to help them out with some free SEO advice.
I came across We Rent Goats today, and loved their eco-friendly idea of clearing weeds and brush with goats, instead of harmful herbicides.
The site opens with a cute sign of a goat carrying a sign around his neck - "will work for food". Nice touch.

Webmasters, bloggers and anyone else trying to make a living off the Internet, and in particular, Web traffic generated Google search, will understand how en

Check out two of the best business SEO tools (Ahrefs vs.

SEO (Search Engine Optimization) for eCommerce sites plays a vital role in driving valuable organic search traffic that converts into sales and revenue.

Would you love to get completely irrelevant traffic from Google's organic search results? How about absolutely no traffic at all?

Restoring Web traffic volumes after a Google algorithmic penalty (especially one like Panda or Penguin) can be a very difficult and, often, fruitles

About two or three months ago I decided to have a quick look at what sites Google consider related to mine using the related: search operator.
To my horror I saw a list of SEO agencies - some of which were no more than a landing page for a paid SEO service (of no doubt dubious quality). Why would Google think this blog is an SEO company?
SME Pals' tagline is 'Start a small business today', and the focus of the site is to inspire entrepreneurs to find a business idea and startup as quickly and easily as possible. Sure, search is a big part of growing an online business, so I talk about it... but is this enough to cause Google to think this blog is an SEO service?

